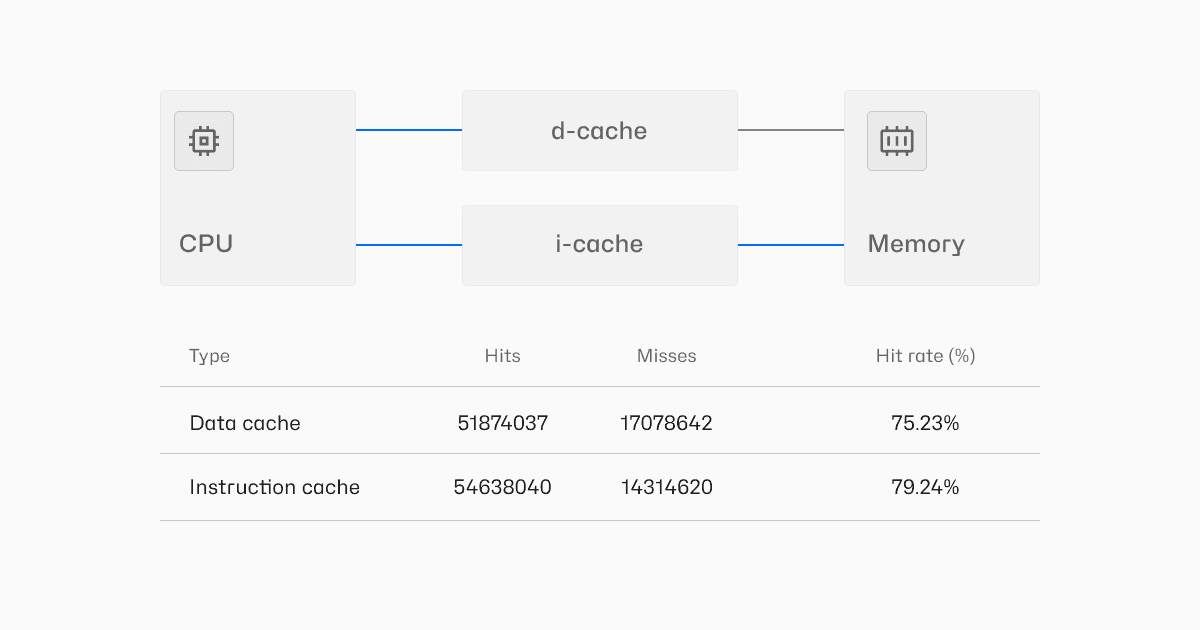
One of the most popular approaches to cross-architecture simulation is based on retranslation of guest architecture code (e.g. on ARMv8-A or other ISAs) to the host architecture (e.g. on x86-64). Performance of the translation process is crucial for effective simulation. To improve that performance, the translated code can be cached, opening up many different optimization approaches.
This internship and thesis project consisted in measuring some aspects of cache usage optimization techniques to identify best strategies for improvement, e.g. by analyzing how the length of blocks changes during the simulation. The studied optimization approaches were measured in Renode simulation for Cortex A78 for Linux and EFR32BG22 for Zephyr, with various payloads (operating systems, bare-metal applications) to compare effects in different scenarios.